发布时间:2020-12-23 01:08:52
一.导言
万维网上有无数的网页,其中包含了大量的信息。有时我们需要从一些网站上提取有趣且有价值的内容。但是无法点击网页手动复制粘贴。我们需要一个能够自动获取网页内容,并按照指定的规则提取相应内容的程序,这个程序叫做爬虫。
网络爬虫的本质是http请求,浏览器是用户主动操作然后完成http请求,而爬虫需要自动完成HTTP请求,网络爬虫需要一个完整的框架来完成工作。
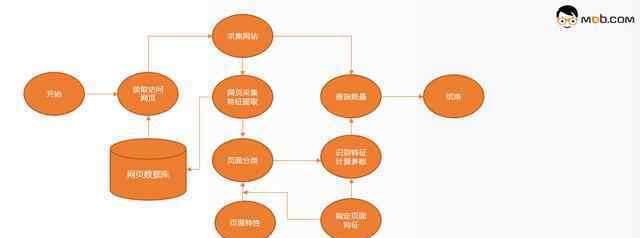
一般来说,一个完整的爬虫生命周期包括URL管理、页面下载、内容提取和持久化。
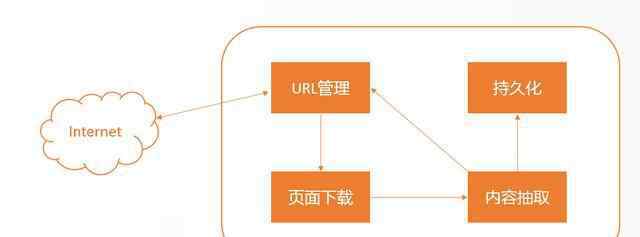
网址管理
首先,url管理器向待爬集添加新的url,判断待添加的url是否在容器中,获取待爬的url,并将该url从待爬集移动到已爬集。
页面下载
下载器将接收到的url传输到互联网,互联网将html文件返回给下载器,下载器本地保存。一般下载器会分布式,一个是提交效率,一个是充当请求代理。
内容提取
页面解析器的主要任务是从获得的html网页字符串中获取有价值的有趣数据和新的url列表。常见的数据提取方法包括基于css选择器的规则提取、正则表达式和xpath。通常,在提取之后,数据将被清理或定制,以将所请求的非结构化数据转换成我们需要的结构化数据。
数据持久性
相关数据库、队列、文件等的数据持久性。便于数据计算和应用对接。
二.爬行动物分类学
Web爬虫一般按照实现的技术和结构分为一般web爬虫和聚焦web爬虫。特征方面,也有增量web爬虫和深度web爬虫。在实际的网络爬虫中,它们通常是这几种爬虫的组合。
通用网络爬虫
通用网络爬虫。一般的网络爬虫也叫全网爬虫。顾名思义,一般网络爬虫抓取的目标资源在整个互联网中。一般网络爬虫抓取的目标数据庞大,抓取范围也很大。正是因为爬行数据是海量数据,所以这类爬虫的爬行性能非常高。这种网络爬虫主要用于大型搜索引擎,具有很高的应用价值。
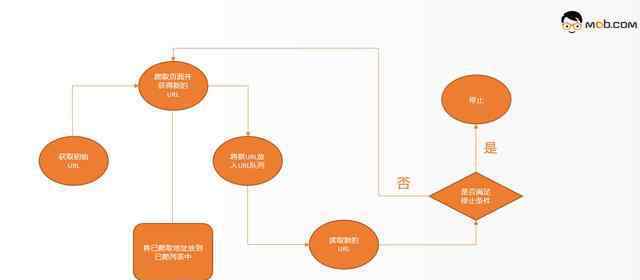
通用网络爬虫主要由初始URL集、URL队列、页面抓取模块、页面分析模块、页面数据库、链接过滤模块等组成。一般的网络爬虫在爬行时会采用一定的爬行策略,包括深度优先爬行策略和广度优先爬行策略。
关注网络爬虫
聚焦爬虫也称为主题爬虫。顾名思义,聚焦爬虫是根据预定义的主题有选择地抓取网页的爬虫。与一般的爬虫不同,聚焦爬虫将目标网页定位在与主题相关的页面中,而不是整个互联网。这时候可以大大节省爬行所需的带宽资源和服务器资源。聚焦Web爬虫主要用于抓取特定信息,主要为特定人群提供服务。
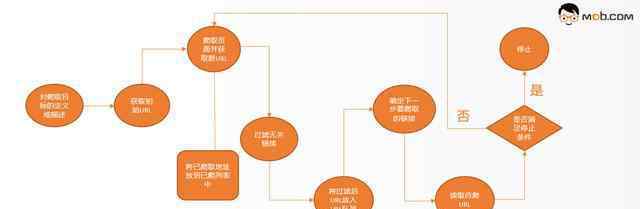
聚焦网络爬虫主要由初始URL集、URL队列、页面抓取模块、页面分析模块、页面数据库、链接过滤模块、内容评估模块、链接评估模块等组成。内容评估模块可以评估内容的重要性。同样,链接评估模块也可以评估链接的重要性,然后根据链接和内容的重要性,先访问哪些页面。
增量网络爬虫
增量网络爬虫,称为增量,对应于增量更新。增量更新意味着只更新已更改的位置,而不更新未更改的位置。因此,在对网页进行爬网时,增量web爬网程序只会对内容已更改的网页或新生成的网页进行爬网,而不会对内容未更改的网页进行爬网。增量web爬虫可以在一定程度上保证被抓取的页面尽可能的新。
深度网络爬虫
深度网络爬虫(Deep Web Crawler),常规的网络爬虫在运行中无法发现隐藏在普通网页中的信息和规则,缺乏一定的主动性和智能性。深度网络爬虫可以捕获深度网页的数据。一般网页分为表层网页和深层网页。表层页面是指传统搜索引擎可以索引的页面,而深层页面只有用户提交一些关键词才能获得。例如,那些内容在用户注册后可见的页面属于深度页面。
3.爬行动物和反爬行动物
爬虫的目的是自动从目标网页获取数据,但这种行为会对目标站点造成一定的压力,对方一般会有反抓取的手段来保护站点性能或数据。因此,在爬行动物的发展过程中,应该考虑反爬行。
在爬虫开发过程中,分布式(代理IP)、异步数据解析(内置浏览器内核)、光学图像识别、模拟验证(模拟请求头、用户代理、令牌)等手段是常见的。Web爬虫会给Web服务器带来巨大的资源开销。当我们写的爬虫数据不能给我们带来价值的时候,我们应该停止不必要的网络请求,减少对互联网的干扰。
一般情况下,站点反抓取会考虑后台访问的统计,拦截单个IP、Session、单个用户-代理访问超过阈值或缺失Referer、Robots协议、异步数据加载、页面动态、请求验证拦截等请求。高端反爬包括混淆、代码不稳定、给假数据(中毒)、行为分析、假链陷阱、字符转图片等等。一般反爬虫策略多用于较低级别的爬虫,不管服务器压力如何,保持访问简单粗暴,另一种是失控或被遗忘的爬虫,一般需要第一时间屏蔽。
鉴于爬虫抓取的数据是目标网站在互联网上发布的公开数据,理论上不可能完全停止爬虫。站点能做的就是增加爬虫的爬行难度,增加爬虫的开发成本,以至于退却。爬虫越高级越难被屏蔽,相应的高级爬虫开发成本也越高。在拦截高级爬虫时,如果成本高到一定程度,爬虫不会给自身带来很大的性能压力和数据威胁,那么就没有必要继续提高成本和对抗爬虫。目前,大多数热门网站在与爬行动物的游戏中,在爬行动物和反爬行动物之间保持平衡。毕竟双方都是想在商业市场上获取利益,而不是不计代价的互相残杀。
文字/暴民马博

ShareSDK轻松实现社交功能,以其强大的App社交分享功能而被开发者熟知和好评;
SMSSDK可以快速集成短信验证功能,帮助开发者打通手机通讯录好友的社交圈;
MobLink打破了App孤岛,实现了Web和App的无缝链接。新用户第一次打开App时,大大提高了用户转化率;
Mob统计分析采用数据驱动产品,精准行为分析+多维数据模型+匹配全网标签+垂直行业分析顾问;
MobPush快速集成推送服务,应对多样的推送场景;
BBSSDK是Discuz论坛的动员解决方案,同步Discuz论坛的数据,实现论坛动员。
ShareREC手机游戏视频分享是ShareSDK图形分享的延伸,可以实现手机游戏的播放和录制功能,从而增强玩家粘性,有效促进推广;
MobAPI为开发人员提供了各种所需的原始数据和稳定的API SERVICE,也消除了自己收集数据的繁琐步骤;
MobPay的各种主流支付渠道,一键即可接入,满足企业多元化需求;
ShopSDK小时快速搭建你的商城系统,商品管理-订单交易-售后退款-完整解决方案,丰富你app的APPlication场景;
MobIM为开发者提供即时通讯消息渠道服务,重点保证通讯的安全性、稳定性和可靠性,支持开发者使用App自带的用户系统或第三方用户系统;
App Factory新的App生产解决方案,可以结合数十种不同类型的App,满足电子商务、生活服务、教育、信息、社交等行业的需求;
截至2017年12月,Mob开发者服务平台覆盖全球超过76亿台设备,SDK下载量超过318万次,移动应用超过36万次。
欢迎分享转载 →反爬虫 五分钟了解爬虫 爬虫与反爬虫的博弈