发布时间:2020-07-30 05:28:57
关注我哦!
◆◆◆
导
语
READ
二分图又称作二部图,是图论中的一种特殊模型。 设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为一个二分图。
二分图的匹配
二分图匹配:
给定一个二分图G,在G的一个子图M中,M的边集{E}中的任意两条边都不依附于同一个顶点,则称M是一个匹配。
极大匹配(Maximal Matching)是指在当前已完成的匹配下,无法再通过增加未完成匹配的边的方式来增加匹配的边数。最大匹配(maximum matching)是所有极大匹配当中边数最大的一个匹配。选择这样的边数最大的子集称为图的最大匹配问题。
如果一个匹配中,图中的每个顶点都和图中某条边相关联,则称此匹配为完全匹配,也称作完备匹配。
求二分图匹配可以用最大流(Maximal Flow)或者匈牙利算法(Hungarian Algorithm)
注意匈牙利算法,除了二分图多重匹配外在二分图匹配中都可以使用。
注:二分图匹配中还有一个hk算法,复杂度为o(sqrt(n)*e)由于复杂度降低较低,代码量飙升而且绝大多数情况下没人会闲的卡个sqrt的复杂度。。在此先不讲了,有兴趣可以自己百度,貌似卡这个算法的只有hdu2389
嘛 首先我们讲解一下匈牙利算法的过程:
匈牙利算法几乎是二分图匹配的核心算法,除了二分图多重匹配外均可使用
匈牙利算法实际上就是一种网络流的思想,其核心就是寻找增广路。
最大匹配
选择边数最大的子图称为图的最大匹配问题(maximal matching problem)
如果一个匹配中,图中的每个顶点都和图中某条边相关联,则称此匹配为完全匹配,也称作完备匹配。
图中所示为一个最大匹配,但不是完全匹配。

增广路径
增广路径的定义:设M为二分图G已匹配边的集合,若P是图G中一条连通两个未匹配顶点的路径(P的起点在X部,终点在Y部,反之亦可),并且属M的边和不属M的边(即已匹配和待匹配的边)在P上交替出现,则称P为相对于M的一条增广路径。
增广路径是一条“交错轨”。也就是说, 它的第一条边是目前还没有参与匹配的,第二条边参与了匹配,第三条边没有..最后一条边没有参与匹配,并且起点和终点还没有被选择过,这样交错进行,显然P有奇数条边(为什么?)
寻找增广路
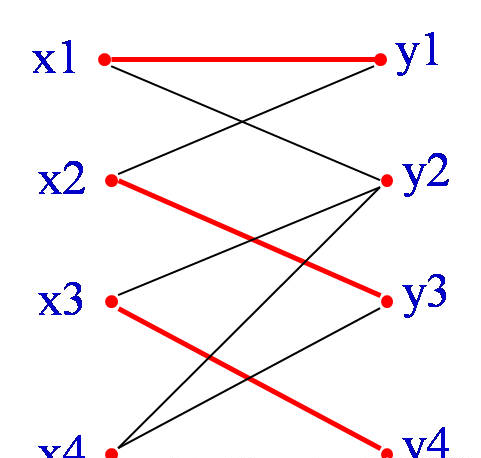
红边为三条已经匹配的边。从X部一个未匹配的顶点x4开始,找一条路径:
x4,y3,x2,y1,x1,y2
因为y2是Y部中未匹配的顶点,故所找路径是增广路径。
其中有属于匹配M的边为{x2,y3},{x1,y1}
不属于匹配的边为{x4,y3},{x2, y1}, {x1,y2}
可以看出:不属于匹配的边要多一条!
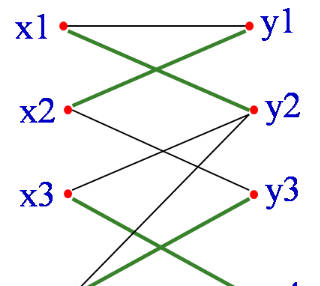
如果从M中抽走{x2,y3},{x1,y1},并加入{x4,y3},{x2, y1}, {x1,y2},也就是将增广路所有的边进行”反色”,则可以得到四条边的匹配M’={{x3,y4}, {x4,y3},{x2, y1}, {x1,y2}}
容易发现这样修改以后,匹配仍然是合法的,但是匹配数增加了一对。另外,单独的一条连接两个未匹配点的边显然也是交错轨.可以证明,当不能再找到增广轨时,就得到了一个最大匹配.这也就是匈牙利算法的思路.
可知四条边的匹配是最大匹配
增广路径性质
由增广路的定义可以推出下述三个结论:
P的路径长度必定为奇数,第一条边和最后一条边都不属于M,因为两个端点分属两个集合,且未匹配。 P经过取反操作可以得到一个更大的匹配M’。 M为G的最大匹配当且仅当不存在相对于M的增广路径。用增广路求最大匹配(称作匈牙利算法,匈牙利数学家Edmonds于1965年提出)
算法轮廓:
置M为空 找出一条增广路径P,通过取反操作获得更大的匹配M’代替M 重复2操作直到找不出增广路径为止我们采用DFS的办法找一条增广路径:
从X部一个未匹配的顶点u开始,找一个未访问的邻接点v(v一定是Y部顶点)。对于v,分两种情况:
如果v未匹配,则已经找到一条增广路 如果v已经匹配,则取出v的匹配顶点w(w一定是X部顶点),边(w,v)目前是匹配的,根据“取反”的想法,要将(w,v)改为未匹配,(u,v)设为匹配,能实现这一点的条件是看从w为起点能否新找到一条增广路径P’。如果行,则u-v-P’就是一条以u为起点的增广路径。cx[i]表示与X部i点匹配的Y部顶点编号
cy[i]表示与Y部i点匹配的X部顶点编号
//伪代码
bool dfs(int u)//寻找从u出发的增广路径
{
for each v∈u的邻接点
if(v未访问){
标记v已访问;
if(v未匹配||dfs(cy[v])){
cx[u]=v;
cy[v]=u;
return true;//有从u出发的增广路径
}
}
return false;//无法找到从u出发的增广路径
}
//代码
bool dfs(int u){
for(int v=1;v<=m;v++)
if(t[u][v]&&!vis[v]){
vis[v]=1;
if(cy[v]==-1||dfs(cy[v])){
cx[u]=v;cy[v]=u;
return 1;
}
}
return 0;
}
void maxmatch()//匈牙利算法主函数
{
int ans=0;
memset(cx,0xff,sizeof cx);
memset(cy,0xff,sizeof cy);
for(int i=0;i<=nx;i++)
if(cx[i]==-1)//如果i未匹配
{
memset(visit,false,sizeof(visit)) ;
ans += dfs(i);
}
return ans ;
}
算法分析
算法的核心是找增广路径的过程DFS
对于每个可以与u匹配的顶点v,假如它未被匹配,可以直接用v与u匹配;
如果v已与顶点w匹配,那么只需调用dfs(w)来求证w是否可以与其它顶点匹配,如果dfs(w)返回true的话,仍可以使v与u匹配;如果dfs(w)返回false,则检查u的下一个邻接点…….
在dfs时,要标记访问过的顶点(visit[j]=true),以防死循环和重复计算;每次在主过程中开始一次dfs前,所有的顶点都是未标记的。
主过程只需对每个X部的顶点调用dfs,如果返回一次true,就对最大匹配数加一;一个简单的循环就求出了最大匹配的数目。
时空分析
时间复杂度: 邻接矩阵:O(n^3) 邻接表:O(nm) 邻接矩阵: O(n^2) 邻接表:O(n+m) 找一次增广路径的时间为: 总时间: 空间复杂度: 邻接矩阵:O(n^2) 邻接表: O(m+n) 邻接矩阵:O(n^3) 邻接表:O(nm) 邻接矩阵: O(n^2) 邻接表:O(n+m) 找一次增广路径的时间为: 总时间: 邻接矩阵:O(n^2) 邻接表: O(m+n)◆◆
好
消
息

欢迎分享转载 →NOIP考点-二分图详解(2)