发布时间:2020-12-23 11:25:46
作者龚红友六
来源|大数据和人工智能
引言:本文将从协同过滤思想简介、协同过滤算法原理介绍、离线协同过滤算法的工程实现、近实时协同过滤算法的工程实现、协同过滤算法的应用场景、协同过滤算法的优缺点以及实施协同过滤算法时需要注意的几个问题等七个方面进行论述。阅读本文后,希望读者对协同过滤的思想、算法原理和工程实现方案有较好的理解,并有能力独立实现一个可用于真实业务场景的协同过滤推荐系统。
作者在《推荐系统产品和算法概述》一文中简要介绍了协同过滤算法。协同过滤算法是整个推荐系统发展史上一个众所周知的算法,发挥着重要的作用,至今仍被广泛使用。
在本文中,作者将根据作者多年的推荐系统研究和工程实践经验,详细阐述协同过滤推荐算法的各个方面。希望对大家学习协同过滤推荐算法有所帮助,提供一些参考。
在正式解释之前,先做一个简单的定义。本文使用“操作”一词来表示用户对主题的各种操作行为,包括浏览、点击、播放、收藏、评论、赞、转发、评分等。
协同过滤简介
协同过滤,字面上包括两个操作:协作和过滤。所谓协同就是利用群体的行为来做出决策(推荐)。生物学上有个共同进化的说法。通过协同作用,群体逐渐进化到更好的状态。对于推荐系统来说,通过用户的不断合作,对用户的推荐会越来越准确。过滤就是从可行的决策(推荐)方案(主题)中找到(过滤)用户喜欢的方案(主题)。
具体来说,协同过滤的思想是通过群体行为找到某种相似性(用户之间的相似性或对象之间的相似性),并通过这种相似性为用户做出决策和推荐。
现实生活中有很多协同过滤的案例和想法。除了前面提到的生物进化是一种“协同过滤”,我认为人类喜欢在相亲中追求“上门服务”,这其实是协同过滤思想的体现。上门其实是建立了一种盲男女之间的“相似性”(家庭背景、出身、生活习惯、生活、消费,甚至价值观可能都是相似的)如果整个社会都有这样的传统和风气,而在真正的“案例”中,“适合对方”的夫妻真的会更和谐。通过“共同进化”的作用,大家会越来越认同这种方式。我个人也认为“对门对对门”是有一定道理的。
协同过滤利用了两个非常简单的自然哲学思想:“群体智慧”和“相似对象具有相似属性”。从数学上讲,群体智慧应该满足一定的统计规律,这是一个朝着平衡稳定状态发展的动态过程。化学和物理成分相同的相似物体越多,它们的外部特征就越相似。这两个想法虽然简单易懂,但因为简单,所以很有价值。所以协同过滤算法原理很简单,但是效果很好,也很容易实现。
协同过滤可以分为两种算法:基于用户的协同过滤和基于对象的协同过滤。下面我们将详细介绍协同过滤的算法原理。
其次,介绍了协同过滤算法的原理
以上部分简要介绍了协同过滤的思想。基于协同过滤的两种推荐算法的核心思想是“物以类聚,人以群分”的简单思想。物以类聚,就是计算出与每个对象最相似的对象列表,然后我们就可以把用户喜欢的对象用相似的对象推荐给用户,也就是基于对象的协同过滤。所谓人分群,就是我们可以向用户推荐一个和用户相似的用户喜欢的题材(但用户从来没有操作过),这就是基于用户的协同过滤。具体思路请参考下图1。
公式1:计算相似度
让我们仔细看看上面的公式。公式的分子是下面矩阵中对应的I、J列的同一行的两个元素(红色矩形中的一对元素)相乘,加上所有行的I、J列元素相乘得到的乘积(其实这里只需要考虑同一行对应的I、J列元素非零的情况,如果I、J列只有一个为零,则乘积也为零)。公式中的分母是第一行的值乘以第一行再按上述类似方法相加,再乘以第一行的值乘以第一行再按上述类似方法相加。
如果我们把k个最相似的对象和每个对象的相似度看作一个列向量,那么我们计算的对象的相似度实际上可以看作是一个每列有k个非零元素的矩阵。
图7:对象相似性矩阵
到目前为止,我们已经通过Spark提供的一些变换操作和工程实现中的一些技巧,计算出了每个对象topK最相似的对象。这种计算方式可以横向扩展,很容易处理大量的用户和对象,最多可能需要增加更多的服务器。
3.2为用户生成推荐
用1中计算出的topK最相似的主题,来说明一下如何为用户生成个性化推荐。生成个性化推荐有两种工程实现策略,一种被视为矩阵的乘积,另一种按照第2节“基于主题的协同过滤”中的公式计算。这两种方法本质上是一样的,只是在工程实现上有所不同。下面我们将分别说明这两种实现方案。
完全个性化推荐,就是给每个用户推荐不同的题材列表。我们在第二节中解释的两种类型的协同过滤算法是完全个性化的推荐方法,因此协同过滤可以用于这种情况。在第三、四节中,我们也明确提出了在工程中实现完全个性化推荐的思想。
下图是电视猫电影猜你喜欢推荐,这是一种完全个性化的推荐范式,可以基于协同过滤算法实现。
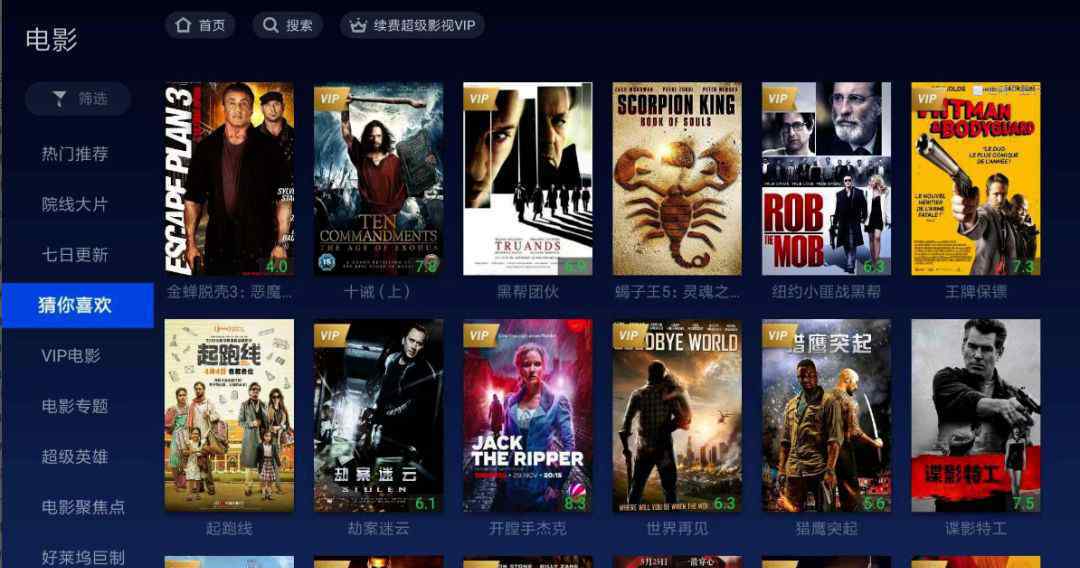
图12:电视猫完全个性化推荐:电影猜你喜欢
5.2与主题相关的主题推荐(正常形式)
第二节虽然没有直接讲对象关联的算法,但是讲的是如何计算两个对象之间的相似度(即图2中打分矩阵的列向量之间的相似度),我们可以用这个相似度来计算与某个对象最相似的k个对象(第三节1给出了对象相似度的工程实现,第四节4也给出了对象相似度近实时计算的实现方案)。那么可以推荐k个最相似的对象作为对象的关联。
下图是电视剧《猫》中类似的电影推荐,是一种与题材相关联的题材推荐范式。这种推荐可以在协同过滤算法的中间过程中基于主题的topN相似度计算来实现。
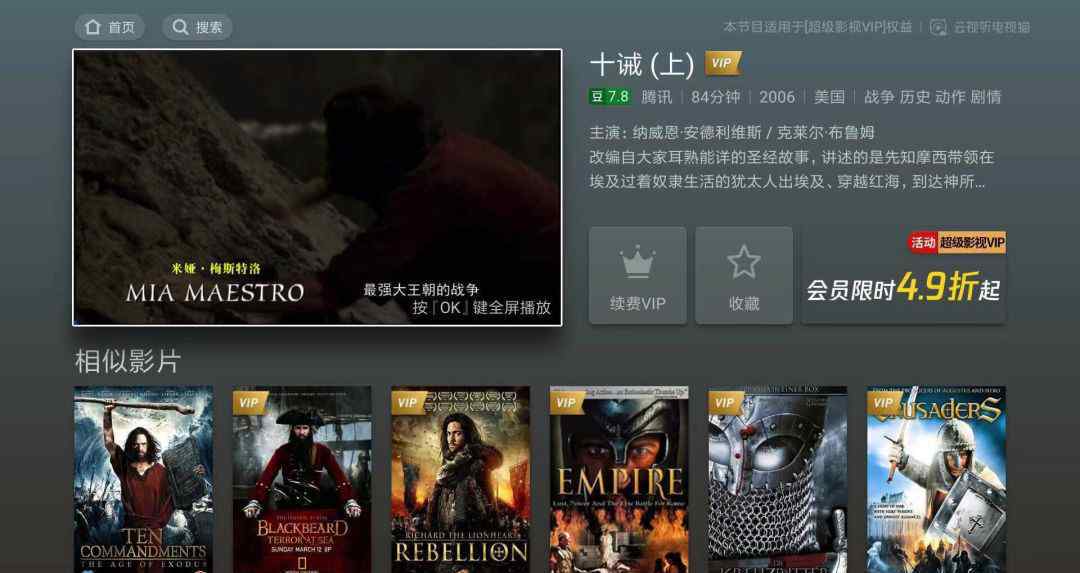
图13:电视猫的题材相关题材推荐:类似电影
5.3其他应用形式和场景
在协同过滤算法的解释中,我们可以将用户或对象表示为向量(用户行为矩阵中的行向量和列向量)。利用用户和对象的向量表示,我们可以对用户和对象进行聚类。
用户聚类后,当然可以用于推荐。将同一个类中其他用户操作的对象推荐给这个用户是一种可行的推荐策略。同时,用户集群化后,也可以用来尝试将长相相似的人商业化(比如广告)。
对主题进行聚类后,也可以用于主题关联推荐,同一类的其他主题可以作为关联推荐结果。此外,在对主题进行聚类后,这些类可以作为编辑或运营团队的特殊主题,作为内容分发的材料。
六、协同过滤算法的优缺点
在前面的部分中,我们对协同过滤算法进行了完整的解释,并提到了协同过滤算法的一些特点。这里简单列举一些协同过滤算法的优缺点,让我们对协同过滤算法有更深入的了解。
优势
协同过滤有很多优点,最大的优点总结如下:
(1)算法原理简单,思想简单
从前面的解释中不难看出,协同过滤算法的实现非常简单,只有了解简单的初等算法和向量、矩阵的基本概念,才能理解算法的原理。整个机器学习领域估计没有更直观简单的算法了。
协同过滤的想法是“物以类聚,人以群分”的简单想法,相信大家都能理解。由于其思想简单,算法原理简单。
(2)该算法易于分布式,能够处理海量数据集
在第三和第四节中,我们解释了协同过滤算法的离线和实时工程实现。应该很容易看出,协同过滤算法很容易通过Spark分布式平台实现,因此通过添加计算节点可以很容易地处理大规模数据集。
(3)算法整体效果很好
协同过滤算法是一种经过行业验证的重要算法,已经在网飞、谷歌、亚马逊和国内大型互联网公司得到了很好的应用。
(4)可以为用户推荐多样新颖的主题
前面提到的协同过滤算法是一种基于群体智能的算法,利用群体行为进行决策。实践证明,可以为用户推荐多样新颖的对象。尤其是群体规模越大,用户行为越多,推荐效果越好。
(5)协同过滤算法只需要用户的行为信息,不依赖用户和对象的其他信息
从前面的算法和工程实践中可以知道,协同过滤算法只依赖于用户的操作行为,可以进行推荐,而不依赖于具体的用户相关和主题相关的信息。通常,用户信息和主题信息是复杂的半结构化或非结构化信息,不便于处理。这是一个很大的优势,因为这个优势让协同过滤算法在业界大放异彩。
劣势
除了上述优点,协同过滤算法也有一些缺点。具体来说,在以下几点,协同过滤算法有弱点,介于推广和优化空之间。
(1)冷启动问题
协同过滤算法依靠用户的行为为用户做出推荐。如果用户行为很少(比如新的在线产品或者用户少的产品),就很难充分发挥协同过滤算法的优势和价值,甚至根本无法为用户做出推荐。这时候可以用基于内容的推荐算法作为补充。
此外,由于新存储的主题只有少量的用户动作,用户动作矩阵中与主题对应的列基本为零,因此无法计算该主题的相似主题,同时该主题也不会出现在其他主题的相似列表中,因此无法推荐该主题。此时,可以通过人工策略在某个位置暴露主题,或者以一定的比例或概率强行添加到推荐列表中,通过收集主题来解决主题无法推荐的问题。
在第七部分,我们将更详细地介绍协同过滤的冷启动解决方案。
(2)稀疏性
现代互联网产品,用户基数大,对象多(尤其是新闻和UGC短视频产品)。普通用户对少量对象只有操作行为。这是因为用户操作行为矩阵非常稀疏,过于稀疏的行为矩阵计算出的对象相似度往往不够准确,最终影响推荐结果的准确性。
协同过滤算法虽然简单,但在实际业务中,为了使其具有更好的效果,最终为业务产生更大的价值,我们在使用该算法时需要注意以下问题。
7.1是采用基于用户的协同过滤还是基于主题的协同过滤
基于主题的协同过滤在互联网产品中普遍使用,因为对于互联网产品来说,用户变化比主题多,用户增长快,主题增长相对慢(这不是绝对的,新闻、短视频等应用主题也增长快),所以基于主题的协同过滤算法效果更稳定。
7.2称重时间
一般来说,用户的兴趣是随时间变化的,行为时间越长,对用户当前兴趣的贡献越小。基于这种思想,我们可以对用户的行为矩阵进行时间加权。在用户评分中加入时间惩罚因子来惩罚长期行为,可行的惩罚方案可以采用指数衰减。例如,我们可以使用以下公式来衰减时间。我们可以选择一个时间作为参考值,比如当前时间。以下公式中的n为标的物的操作时间与参考时间不同时的天数(n=0,w(0)=1时)。
7.3关于用户对主题的评分
在真实的业务场景中,用户可能不一定对题材打分,只对运营行为打分。这时候我们可以用隐式反馈来做协同过滤,虽然隐式反馈的效果可能更差。
但同时也可以通过一些方法和技巧间接得到内隐反馈的得分。主要有以下两种方法。通过这两种方法得到分数是非常直观的,效果肯定比直接用0或者1进行隐式反馈要好。
虽然很多情况下用户的反馈是隐含的,但是用户的操作行为是多样化的,包括浏览、点击、赞、购买、收藏、分享、评论等。我们可以根据这些隐性行为的投入程度(投入时间成本、资金成本、社会压力等)对这些行为进行人工打分。,投入成本越高,得分越高),如浏览到1分,赞到2分,转发到4分等。这样就可以根据用户的不同行为生成差异化的评分。
用于音乐、视频、文章等。,我们可以记录用户在这些主题上花费的时间来计算分数。例如,如果一部电影的总长度是100分钟,如果用户看了60分钟后退出,那么我们可以给用户6分(以10分制为标准,因为用户看了60%,所以他得了6分)。
7.4相似性计算
在解释协同过滤算法时,我们需要计算两个向量的相似度。本文采用余弦余弦相似度。其实计算两个向量相似度的方法有很多。余弦余弦是一种在很多场景下都被证明工作良好的算法,但并不是所有的场景都是最好的余弦余弦,需要在不同的场景下进行尝试和比较。这里简单列举一些常用的相似度计算方法,供大家参考。
(1)余弦相似
余弦的计算公式我已经讲得很详细了,这里就不赘述了。需要指出的是,对于隐式反馈(用户只点击不评分),向量的元素不是1就是0,直接使用余弦公式不是很有效。参考文献5给出了更好的隐式反馈计算公式(见下图14),其中用户U给主题P打分(对于隐式反馈,分数为0或1,但是参考文献5对于用户的不同隐式反馈给出了不同的分数,而不是一直用1,比如浏览到1分,收藏到3分,分享到5分等。,以用户U为主题P的所有隐性反馈行为中得分最高的)。
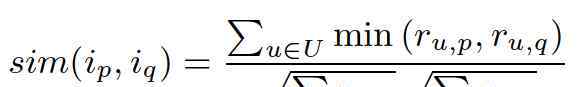
图14:用于计算隐式反馈相似性的优化公式,类似于余弦公式
(2)皮尔逊相关系数
皮尔逊相关系数是线性相关系数。皮尔逊相关系数是用于反映两个变量之间线性相关程度的统计量。具体计算公式如下图15所示,其中和为两个向量,和为这两个向量的平均值。参考文献9介绍了如何使用皮尔逊相关系数进行协同过滤。有兴趣的读者可以参考一下学习。
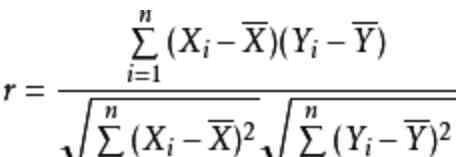
图15:皮尔逊相关系数的计算公式
(3)雅克卡系数
Jaccard系数用于计算两个集合之间的相似度,也适用于隐式反馈型用户行为。假设两个对象,操作过这两个对象的用户是:和,那么Jaccard系数的计算公式如下:
7.5冷启动问题
在谈到协同过滤算法的缺点时,都说协同过滤算法会有严重的冷启动问题,主要表现在以下三个方面:
◆
◆
60+科技咖啡馆在2019 AI ProCon与您见面!会议的早鸟票已经售完,打折票限速35%...2019 AI开发者大会将于9月6 -7日在北京举行。这次AI开发者大会有哪些亮点?一线公司有哪些大牛在关注?AI行业的趋势是什么?2019 AI开发者大会,听大牛分享,专注技术实践,与千万开发者共同成长。
欢迎分享转载 →协同过滤 从原理到落地,七大维度读懂协同过滤推荐算法